
Meet Inception: A new paradigm in language modeling
Davis Treybig
Nov 6, 2025
The “foundation model” category has thus far been characterized by two primary model architectures - autoregressive transformers that produce output tokens one by one, and diffusion models which learn to incrementally turn noise into a structured output.
If you ask the typical machine learning researcher about these architectural paradigms, you will hear that while diffusion models are effective for generative non-text modalities (e.g. image, video, 3D), autoregressive models are very well suited to language modeling.
Indeed, all mainstream ChatGPT-style products utilize the autoregressive (“AR”) architecture, and it is taken as essentially a truism that diffusion architectures don’t map well to language. Myriad reasons exist for why this is the case - such as language being a “discrete” space (e.g. only certain words are valid), language output length being difficult to predict whereas image/video output tends to be more fixed (e.g. 1920x1080 pixel image), and the fact that humans of course output text one word at a time.
However, it is interesting to consider whether these are structural barriers, or simply research questions to be solved. Diffusion has a number of extremely compelling properties - most notably being a more parallel process that is, correspondingly, much faster than autoregressive generation. If one could solve the technical challenges preventing diffusion from being applied to language, might you end up with a better form of large language model? While various researchers poked and prodded at this line of thinking over the past few years (e.g. 2023 blog), Stefano Ermon, Volodymyr Kuleshov, and Aditya Grover, machine learning professors at Stanford, Cornell, and UCLA respectively, were the first to seriously ask this question and consider this (quite non-consensus) research direction.
Their early research, especially “Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution” and “Simple and Effective Masked Diffusion Models”, was the first to demonstrate how to train discrete diffusion models for language which actually mirrored smaller-scale auto-regressive large language models in quality. In fact, the former paper actually went on to win best paper at ICML 2024, one of the premiere machine learning conferences in the world.
These exciting results ultimately led the three of them to start Inception Labs, a research lab dedicated to exploring the potential of diffusion language models in the summer of 2024. Just 9 months after starting the company, they went on to release Mercury, a frontier-scale diffusion large language model of similar quality to models such as GPT-Nano and Claude Haiku, but with 10x the speed (or more).

What had started as a niche research exploration just a few years earlier had quickly become something seemingly disruptive to the mainstream way large language models are developed.
We had been following the Inception team closely since they founded the company thanks both to our long-standing relationship with Volo, who formerly founded a different IE portfolio company, Afresh, as well as by being quite aware of Stefano’s early papers on discrete diffusion models. Once we saw Mercury, we knew we had to invest into what was likely the first major architectural innovation in large language models since the transformer paper.
And so today, we’re excited to announce our investment into Inception’s Series Seed.
Ubiquitous, invisible AI assistance
If you try Mercury, the first thing you’ll notice is its speed. It’s not just pretty fast - it’s blazingly fast, unlike any LLM you’ve used before. Indeed, Mercury defines a new pareto for speed vs. quality in language model benchmarks, and is actually faster than running standard LLMs on extremely speciality hardware such as Cerebras.
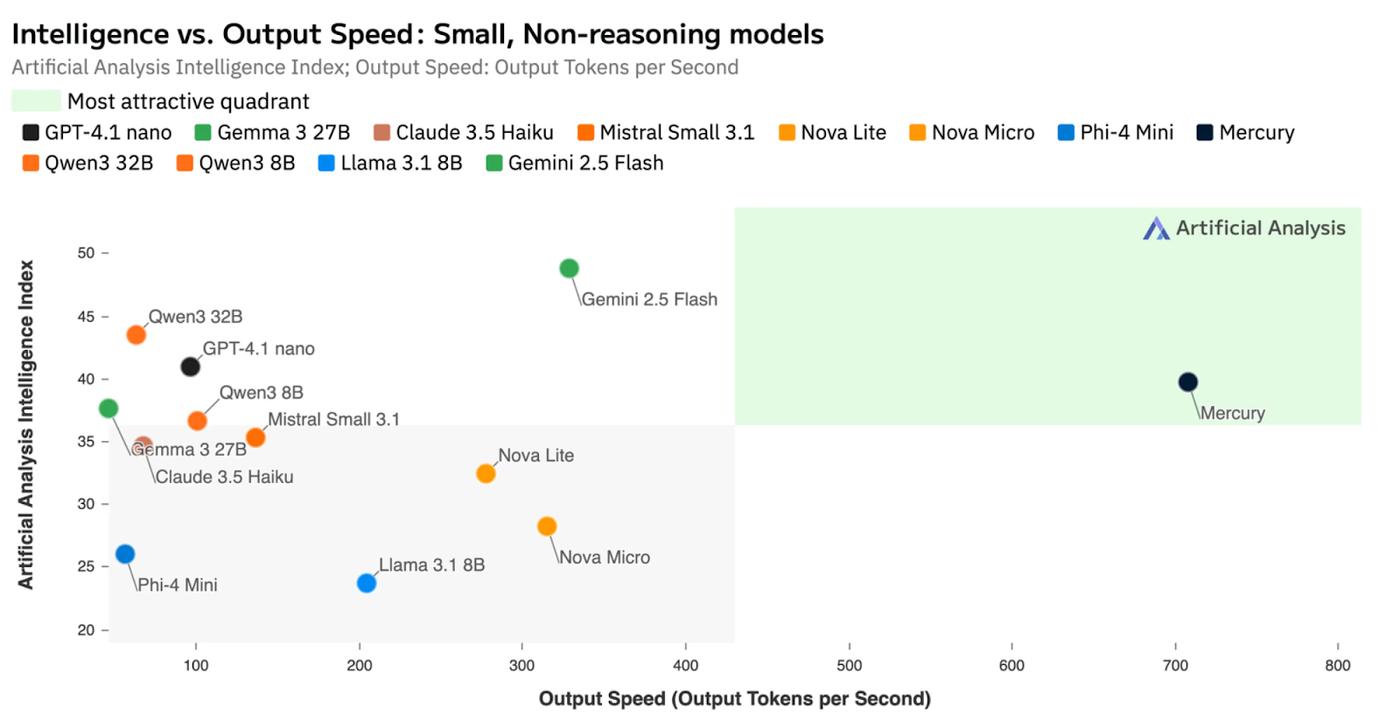
Today, Mercury is used by a number of companies such as Continue, OpenCall, Buildglare, and many more for latency-constrained use cases such as coding autocomplete & voice agents.
While most model labs are focused on building the most intelligent, long running, asynchronous agents - many of most delightful AI products feel instant, invisible, and real-time, where the model preserves your flow and acts as an extension of your thinking.
We suspect that many of the low latency use cases that have become commonplace in AI coding tools - such as autocomplete, next edit, apply edit, and similar - will become universal primitives that exist in basically all software products. Any time a knowledge worker takes any action in any product, an AI copilot will be there to review, assist, or help complete that work.
Achieving this will require continuing to push the frontier of quality while maintaining ultra-low latency, and we think Inception is particularly well positioned to do this.
Beyond speed: Diffusion LLMs promise a new foundation for language modeling
However, speed is just the beginning. Diffusion brings a host of new possibilities that haven’t yet been fully explored in language modeling.
For instance, ControlNet-style conditioning can be applied to text generation - allowing developers to natively enforce structured output formats (like JSON schemas in code generation). Diffusion architectures lend themselves to multimodal modeling, unifying text, image, and video generation in a single framework. Diffusion models are also very low-memory, making them well suited to run in embedded scenarios - whether on-device or in a browser.
Perhaps most intriguingly, diffusion may unlock new approaches to long-form reasoning. Autoregressive LLMs accumulate errors as they think step by step; once a reasoning chain goes off course, it’s hard to recover. Diffusion models, by contrast, can edit their own intermediate steps in place, potentially enabling stronger reasoning and self-correction.
We see Inception as one of the first truly novel architectural directions for language modeling since the birth of LLMs themselves. Mercury is just the start of what will likely become a rich ecosystem of diffusion-based models - faster, cheaper, more controllable, and increasingly capable.
We’re deeply grateful to work with Volo, Stefano, and Aditya on this journey, and to back their vision for the next chapter of generative AI. If you’re trying to build a faster, more fluid, or more magical AI product - you should be building on Inception’s models.
Meet Soffi: the first truly collaborative workplace for product development
Over the last few years, AI has undeniably transformed the pace of software engi...
How Agents Use Systems Differently
Increasingly, coding agents are the ones provisioning and interacting with syste...

A decade of software infrastructure
Today, we are excited to announce Kenneth Auchenberg is joining the team at Inno...

When Machines Build for Machines
For as long as technology has existed, it has been built by humans, for humans....

Our monthly dispatch for the technically curious